Pipeline (skypy.pipeline)¶
The pipeline package contains the functionality to run a SkyPy
simulation from end to end. This is implemented in the Pipeline
class and can be called using the skypy command line script.
Running skypy from the command line¶
skypy is a command line script that runs a pipeline of functions defined in
a config file to generate tables of objects and write them to file. For example,
you can use skypy to run one of the Examples and write the outputs to
fits files:
$ skypy examples/galaxies/sdss_photometry.yml sdss_photometry.fits
To view the progress of the pipeline as it runs you can enable logging using the
--verbose flag.
Config files are written in YAML format and read using the
load_skypy_yaml funciton. Each entry in the config specifices
an arbitrary variable, but there are also some particular fields that SkyPy uses:
parameters: Variables that can be modified at executioncosmology: The cosmology to be used by functions within the pipelinetables: A dictionary of tables names, each resolving to a dictionary of column names for that table
Every variable can be assigned a fixed value as parsed by pyyaml.
However, variables and columns can also be evaluated as functions. Fuctions are
defined as tuples where the first entry is the fully qualified function name
tagged with and exclamation mark ! and the second entry is either a list
of positional arguments or a dictionary of keyword arguments. Variables
and columns in the pipeline can also be referenced by their full name tagged
with a dollar sign $. For example:
parameters:
hubble_constant: 70
omega_matter: 0.3
cosmology: !astropy.cosmology.FlatLambdaCDM
H0: $hubble_constant
Om0: $omega_matter
n_galaxies: 1000
tables:
galaxies:
redshift: !skypy.galaxies.redshift.smail
z_median: 1.0
alpha: 1.5
beta: 2.0
size: $n_galaxies
When executing a pipeline, all dependencies are tracked and resolved in order using a Directed Acylic Graph implemented in networkx.
Using a pipeline from other code¶
SkyPy pipelines can be executed programmatically from other code. Consider the following example configuration:
parameters:
median-redshift: 1.0
galaxy-redshifts: !skypy.galaxies.redshift.smail
z_median: $median-redshift
alpha: 1.5
beta: 2.0
size: 1000
The Pipeline class can be used to load the configuration file
and run the resulting pipeline. If the configuration defines a parameters
section, the definition can be accessed and individual parameter values can be
changed for individual executions of the pipeline:
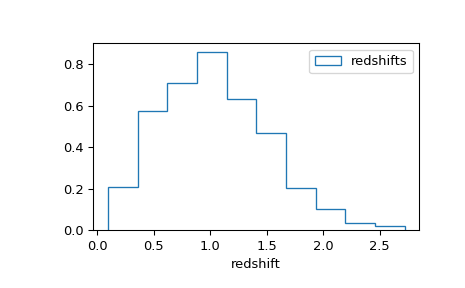
import matplotlib.pyplot as plt
from skypy.pipeline import Pipeline
# read the example pipeline
pipeline = Pipeline.read('examples/pipeline.yml')
# run the pipeline as given
pipeline.execute()
# plot the results for the given parameters
plt.hist(pipeline['galaxy-redshifts'], histtype='step', density=True,
label='{:.2f}'.format(pipeline.parameters['median-redshift']))
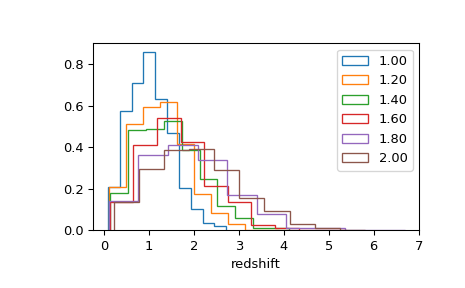
# change the median redshift parameter in a loop
for z in [1.2, 1.4, 1.6, 1.8, 2.0]:
# median redshift parameter
parameters = {'median-redshift': z}
# run pipeline with updated parameters
pipeline.execute(parameters)
# plot the new results
plt.hist(pipeline['galaxy-redshifts'], histtype='step', density=True,
label='{:.2f}'.format(parameters['median-redshift']))
# show plot labels
plt.legend()
plt.xlabel('redshift')
Reference/API¶
skypy.pipeline Package¶
This module provides methods to pipeline together multiple models with dependencies and handle their outputs.
Functions¶
|
Read a SkyPy pipeline configuration from a YAML file. |
Classes¶
|
Class for running pipelines. |